
The two models fueling generative AI products: Transformers and diffusion models
Uncover the secrets behind today's most influential generative AI products in this deep dive into Transformers and Diffusion models. Learn how they're created and how they work in the real-world.

To most people, even experienced data scientists and software engineers, generative AI seems like a big black box. And that's because it sort of is. Generative machine learning models, the workhorses behind today's most popular generative AI products, actually do suffer from a lack of interpretability and transparency. This means that even the people training these models have a hard time understanding why the model chooses to respond with a particular output.
Despite the somewhat mysterious nature of generative models, it's important to understand that generative models don't just "create something out of nothing." Instead, they "create something out of a lot of something elses." There are methods and algorithms behind what appears to be "magic." Understanding the algorithms behind generative modeling empowers you to choose how you interact with AI and what credence you give its outputs.
This article will provide you with an overview of how generative models work, why they work so well, and explain how to build and use the two most impactful models that power some of the best generative AI products on the market today: Transformers and diffusion models.
What are generative models?
The objective of machine learning is to develop models that can learn from and make predictions or decisions based on data. Given the broad spectrum of industries leveraging machine learning and the diverse problems it tackles, there's no “one-size-fits-all” solution or model applicable to all machine learning tasks. Model selection depends on a number of factors, including the nature, quality, and size of available training data as well as desired model performance and the task to be completed.
Generative modeling involves training models to learn to predict probabilities for data based on learning the underlying structure of the input data alone. This means that when the goal of the task is to create novel data that closely resembles existing data, generative machine learning models are the best options. AI products that generate new media, whether it be text, images, or audio are all powered by generative models. Generative AI products range from chatbots, like ChatGPT, to prompt-based photo editing, like Adobe Firefly. While the media that these products produce and the way do it varies, they all rely on generative AI models. As with all forms of artificial intelligence, understanding how they work and what their limitations are is crucial, particularly when it comes to data generation. Now that we've defined generative models, let's take a look at how they actually work.
How do generative models work?
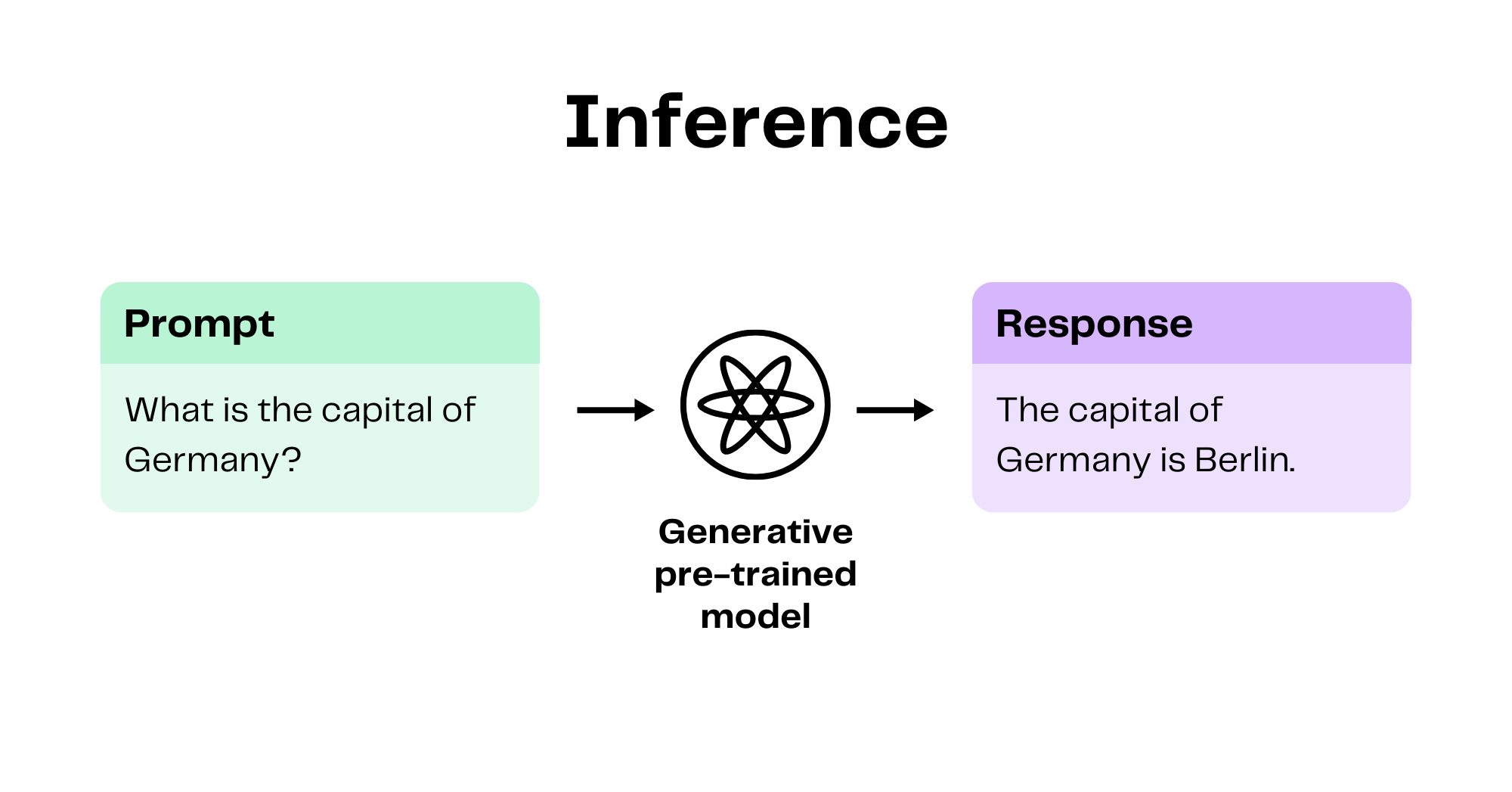
It's important to understand the distinctions between how the generative models are used and how generative models are created. The process of sending input and receiving a response from an existing machine learning model is called inference. An example of this would be asking ChatGPT "What is the capital of Germany?" The underlying language model will receive this input and likely respond with something like "The capital of German is Berlin." In this case, the input to the model can also be called a prompt. Most generative AI products on the market today require a prompt of some sort and will respond with the generated output, whether that be in text, image, audio, or video form.
The process of creating generative models is called the training phase. All machine learning models need to be supplied with training data, but the manner in which they learn from that data varies. Generative models focus on understanding the intrinsic structure of the training data, including patterns and associations among the data.
For instance, if you feed a generative model images of cats and dogs, it will learn which types of combinations of physical features (ear shape, fur color, nose shape, eye color) tend to be indicative of cats versus dogs. They do this by learning something called a joint probability distribution, the probability of certain features in the input data occurring together. Once a generative model has this understanding, it can create new data that are similar to what it was trained on.
An important feature of generative models is that they don’t require labeled data in order to create a model. This means that you can feed a generative model pictures of cats and dogs without supplying the accompanying labels for each of the pictures, and the model will still learn how to determine the difference between them as well as learn how to generate images that look like realistic cats and dogs. This is a game changer because labeled data can often be imbalanced and hard to come by in the real world.
The ability to learn from large amounts of unlabeled data allows generative models to develop excellent global knowledge. This is one factor that makes generative models so effective. Another factor is their ability to leverage vast amounts of data for pre-training and their capability to be fine-tuned, as we'll explore in the following section.
Why do generative models work so well?
They are pre-trained on lots of data
Recent advancements in training techniques and improved computation power mean that generative models can learn from massive amounts of unlabeled data. For instance, the Common Crawl Dataset, contains several petabytes of text data scraped from the internet since 2008. Datasets like Common Crawl are used in the pre-training process, which refers to the initial phase of training where a model learns from a large amount of general data before it is fine-tuned on a specific task. Models that undergo the pre-training process are called foundation models, and are designed to learn a broad base of knowledge from large-scale datasets.
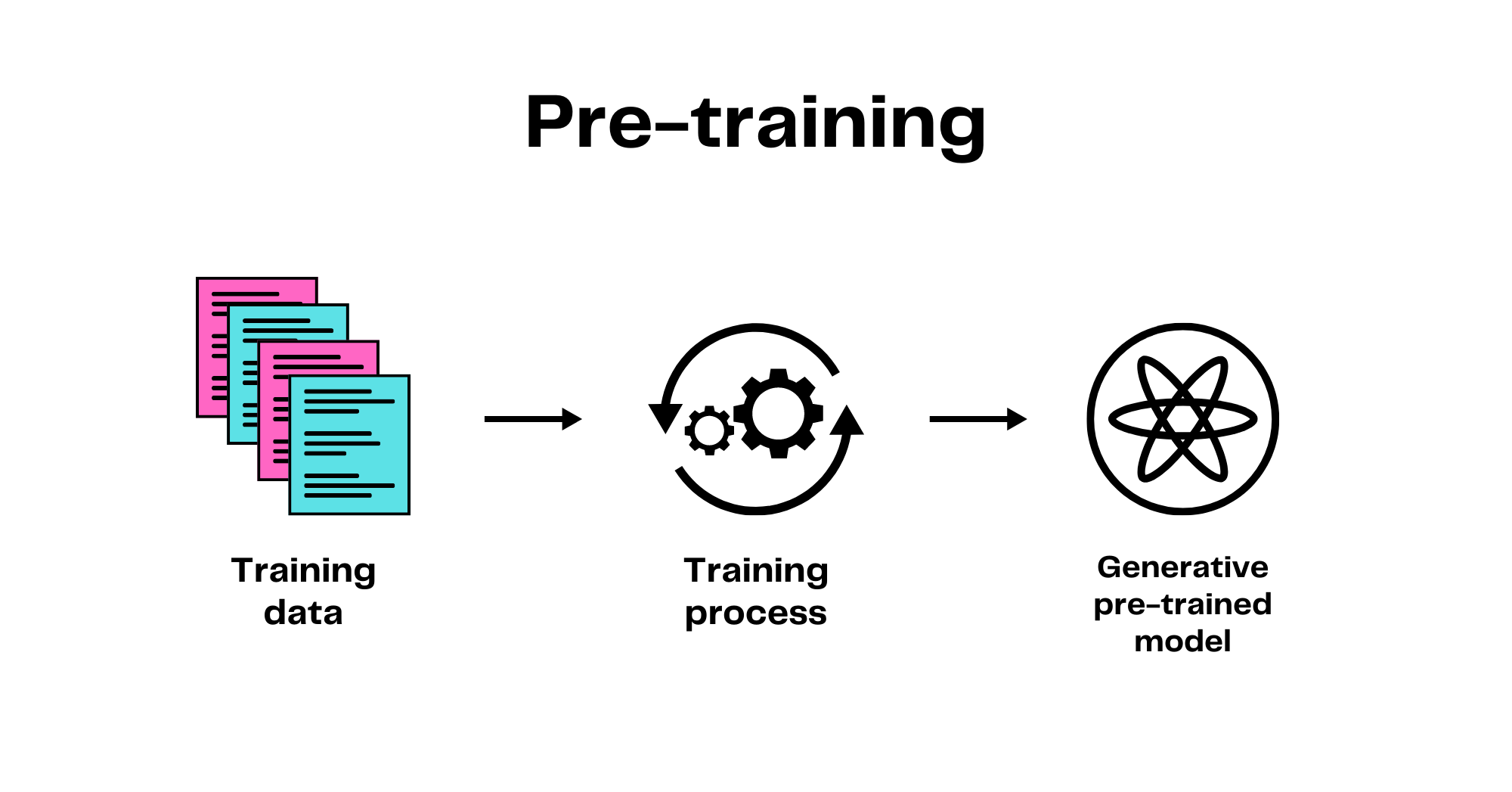
Here are a few examples of generative foundation models trained on large datasets:
- LLaMA (Meta AI) is a large language model pre-trained on 1.4 trillion tokens (individual units of text).
- Stable Diffusion (Stability AI) is an image generation model pre-trained on 2.3 billion English-captioned images from the internet.
- GPT-3 (OpenAI), the predecessor to ChatGPT and GPT-4, was pre-trained on 300 billion tokens.

While the ability to learn from enormous datasets is a crucial aspect of the effectiveness of generative modeling, it's only part of the story. Another key to their power lies in the concept of fine-tuning.
They build on each other
Foundation models oftentimes undergo a process called fine-tuning, which involves additional training on a smaller, task-specific dataset to specialize the model's capabilities for a specific application or domain. This process tailors the broad knowledge captured by the foundation model, enhancing its performance on the targeted tasks. Many of the best-funded and most hyped generative AI products are powered by models that are fine-tuned versions of larger models. Here are a few examples:
- Tabnine's AI-powered coding assistant for developers uses a model fine-tuned on open-source (public-facing) code.
- Writesonic's AI-powered writing assistant for creators and content marketers uses a version of GPT-4 fine-tuned on blog posts, Google ads, and other related content.
- PromptPerfect, by Jina AI, is a tool that helps you create better, more specific prompts for ChatGPT and is fine-tuned on a collection of such prompts.
Generative models build on each other, inheriting the capabilities and strengths of prior models while incorporating novel advancements in algorithms, architectures, and training techniques. This process enables subsequent models to learn more complex patterns and representations while maintaining a broad knowledge base, enhancing their performance, and broadening their applicability.
So far we've talked about generative modeling in a broad sense. In practice, there are several different types of generative models, with their own unique architectures, advantages, and limitations. In the next section, we'll break down the cutting-edge and relevant types of generative models.
Two types of generative models
In the universe of generative models, two types stand out due to their effectiveness and widespread use: Diffusion models and transformers. These groundbreaking architectures have redefined the landscape of machine learning applications, and understanding their intricacies provides valuable insight into how models generate new data. They are also the workhorses behind many of the most well-known generative AI products, namely those which generate text and images from prompts.
Transformer models
Transformer-based models have revolutionized the way that machine learning models interact with text data, both in terms of analyzing (classifying) it and generating it. Transformers can be made up of a combination of encoders and decoders or just decoders. For the purpose of this article, we will focus on decoder-only models, because they are specifically trained for text-generation tasks. These types of models are also referred to as Generative Pre-Trained Transformers (GPTs), which is where ChatGPT and the rest of OpenAI's GPT models get their name from.

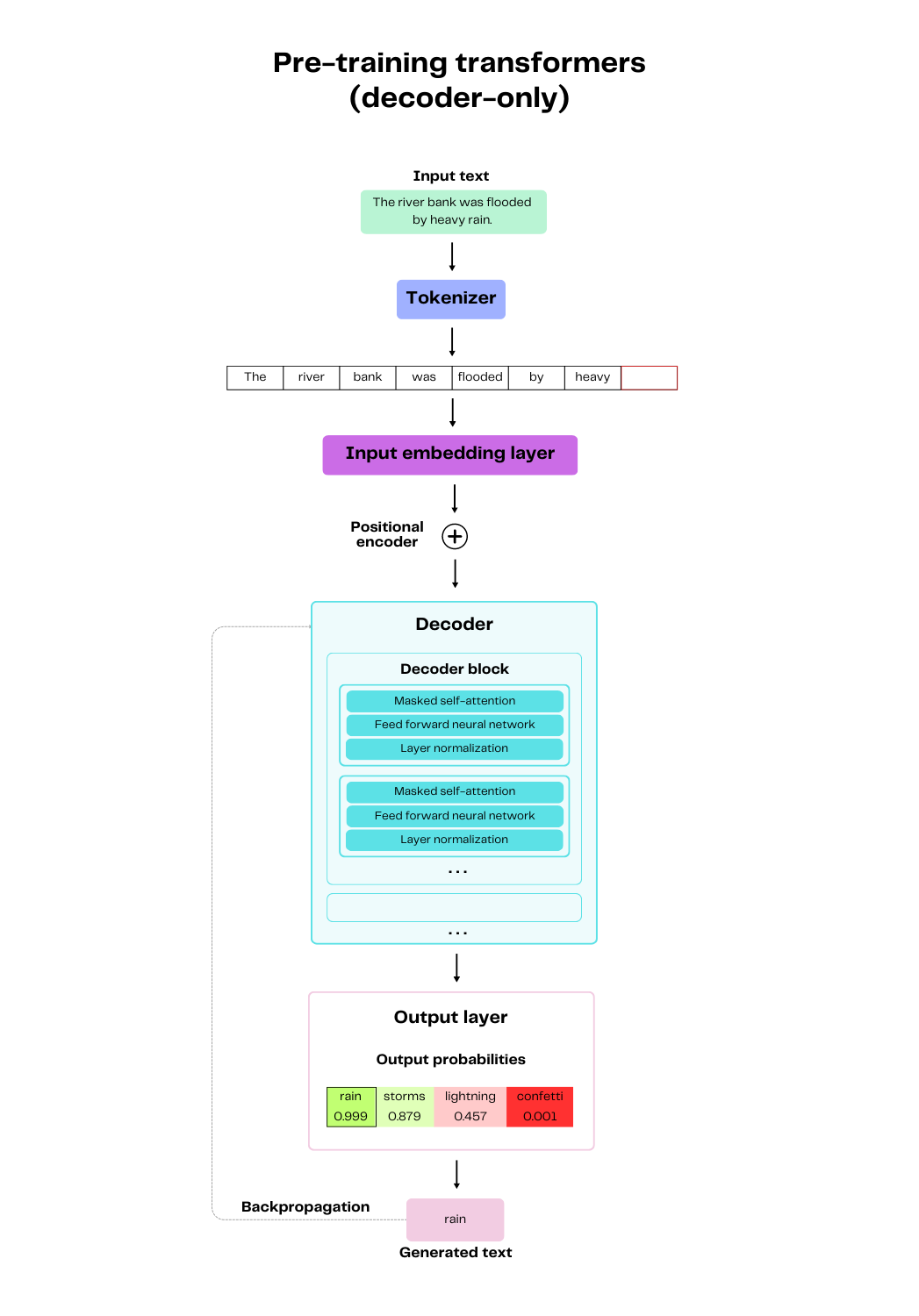
Pre-training a decoder-only transformer model primarily relies on a type of task called language modeling. This task essentially involves predicting the next word in a sequence given the previous words, which is also known as autoregressive language modeling. Let's unpack the training process involved in teaching a language model to predict the word "rain" in the sentence, "The river bank was flooded by heavy rain."
Pre-training decoder-only Transformers for generative tasks
The first step in the pre-training process is tokenization, which breaks down the full text in the training data into individual words or subwords. These tokens are then passed through the input embedding layer of the model, which converts the tokens into high-dimensional vectors (arrays of numbers) that the model can understand. These vectors are then augmented with positional encodings, which give important information to the model about the order of the words in the sequence.
These vectors are then fed to the main part of the model, which consists of several decoder blocks. Each of these blocks is equipped with a mechanism called masked self-attention, which allows the model to weigh the importance of each input word when predicting the next word. Self-attention allows the model to comprehend and capture intricate dependencies between words in a sentence, significantly improving the model's understanding of context and language nuances and is a critical feature in the transformer architecture.
Next, the data is fed to a feed-forward neural network, which helps the model learn more complex representations of the data. To stabilize and speed up the process, each of these components is followed by layer normalization, which balances the scale of the inputs across the network layers, enhancing model stability and accelerating the learning process.
The output of the final decoder block is passed through a linear layer, which is a simple transformation of the data, followed by a softmax operation. This essentially means that the output from the last decoder block is used to calculate the likelihood of all possible next words. The model then picks the word with the highest likelihood as its prediction. In this case, the model would pick the word "rain" to complete the sentence, "The river bank was flooded by heavy ___." The output, "rain" is then compared to the full sentence present in the training data. These comparisons form the basis of the loss (error), which is used to update the model parameters through backpropagation. This is performed iteratively over multiple epochs (passes) of the data until the model's performance either plateaus or begins to degrade.
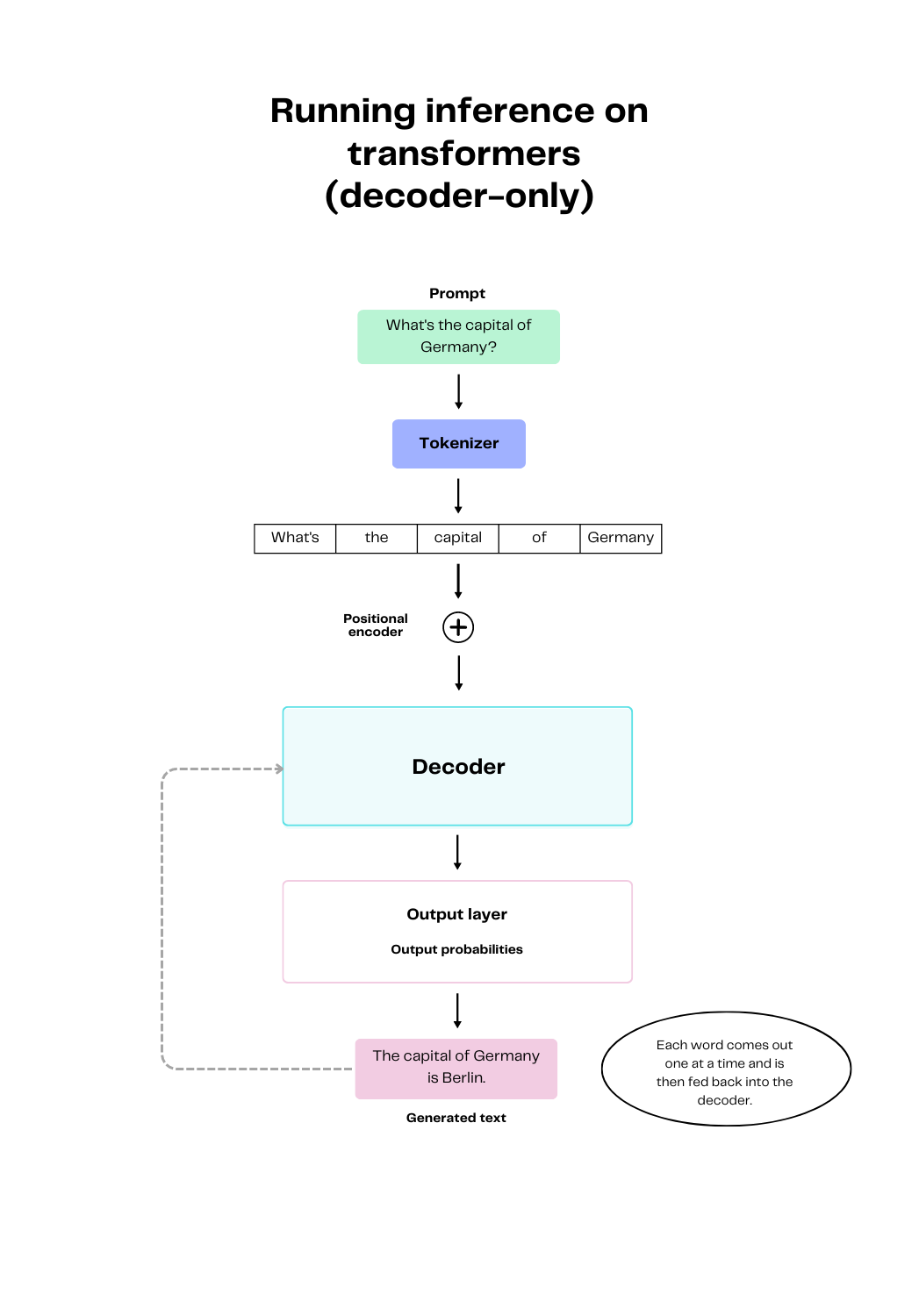
Running inference on transformers
After the model has been successfully pre-trained or fine-tuned, it's ready to be used to make predictions. Running inference on a transformer model is relatively straightforward. You start by feeding the model your text prompt. Just as in the pre-training process, the input text is transformed into something the model can understand by going through the processes of tokenization and positional encoding. The resulting output of this text transformation is then fed to the decoder and the output layer. The model returns the output of the inference one word at a time. Each resulting word is then fed back into the decoder to iteratively predict the next word in the sentence, until completion.
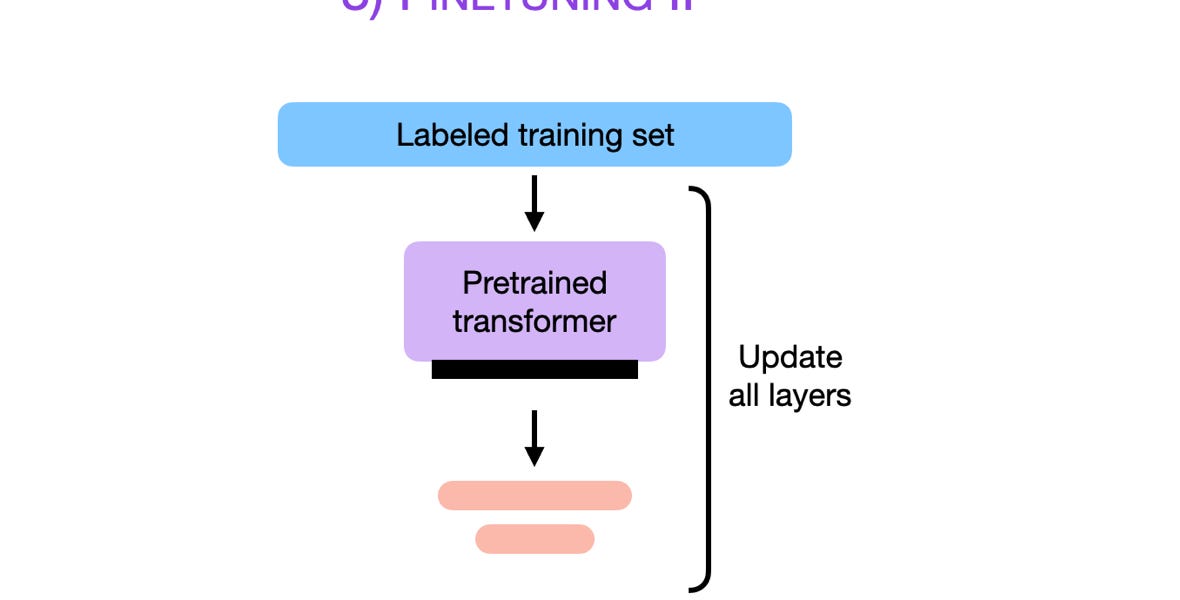
Advantages of Transformer models
Transformer models have revolutionized the field of natural language processing (NLP), a subset of AI that focuses on training models to understand, interpret, and generate human language. Decoder-only models are especially good at generating novel text, given a prompt or set of instructions.
Here are some NLP tasks that decoder-only transformers perform particularly well:
- Language generation - Generating coherent and contextually relevant text, such as in chatbots or language models.
- Text summarization - Condensing long documents or pieces of text into shorter, more manageable summaries while retaining key information and meaning.
- Text style transfer - Rewriting text to match the style of a specific piece of existing text.
- Machine translation - Achieving state-of-the-art results in translating text between different languages.
Additionally, these models can be refined with lesser amounts of data to enhance their performance on specific tasks, through the process of fine-tuning. This means that you can leverage the knowledge from large language models pre-trained on massive amounts of data (at someone else's expense), and fine-tune them using a comparatively smaller, task-specific dataset. In fact, many of the best large language models (LLMs) out there today are models that are fine-tuned on previously released LLMs. Check out Sebastian Raschka's excellent blog post to learn more about fine-tuning.
Limitations of Transformer models
Transformers, despite their strengths, also experience several prominent challenges and constraints. Historically, the top-performing generative text models are the most expensive and difficult to pre-train. And while we are starting to see examples of models that cost a fraction to pre-train while maintaining much of the accuracy of the best benchmark models, like Stanford's Alpaca, these models are not perfect by any means and can sometimes generate toxic content.
Here are some of the top challenges and limitations that decoder-only generative text models face:
- Computational complexity - Pre-training transformers from scratch requires significant computational resources, including state-of-the-art hardware and high compute costs.
- Training data requirements - Transformer models often require large amounts of training data, which may be difficult to access, especially if licensing and copyright issues are a concern.
- Interpretability - The complex and distributed nature of transformer models can make it hard to understand how they make their predictions and are sometimes referred to as a "black box."
- Hallucination - When used to generate text, models with the Transformer architecture are known for generating wildly inaccurate (and sometimes toxic) responses in a convincing manner.
- Model bias - Generative models always exacerbate the biases of their training data. The Brookings Institution found that ChatGPT exhibited a left-leaning political bias when presented with a sequence of statements on political and social matters.
 _jeremybaum
_jeremybaum
In summary, decoder-only transformer models are excellent at performing generative text tasks because they are able to "predict the next word" so well. This ability is a result of the model's ability to understand the contextual relationships between words and phrases, including their meaning and order in a piece of text. While top-tier generative text models are generally expensive to pre-train, the ability to fine-tune these models means that businesses and researchers can train models that inherit the high-performance capabilities of larger models. And although we are living in a golden age of LLMs, we still need to be aware of their performance limitations.
Like what you've read so far?
Become a subscriber and never miss out on free new content.
Diffusion models
The first diffusion model, introduced in 2015, was inspired by non-equilibrium statistical physics. It proposed a novel method for generating novel data by iteratively destroying data structures through the process of diffusion and teaching a model to undo the destruction and reconstruct the data.
Diffusion models are inspired by the process of diffusion, which describes the spreading of particles from a dense space to a less dense space. Think about dropping a drop of blue food coloring into a beaker of water. Before the food coloring reaches the water, its blue-colored molecules are packed into a highly concentrated little droplet. Once the droplet hits the water, the blue-colored molecules gradually spread out, turning the water blue.
The same thing can happen with images. Just as the food coloring disperses into the water, an image can be transformed into a noisy version where its pixels are spread out and scrambled up, making the original image unrecognizable. This is part of how diffusion models are pre-trained. Images in the training dataset undergo the process of diffusion until the pixels disperse into large arrays of random static that no longer resemble images. After diffusion occurs, the model essentially teaches itself to undo the diffusion and restore the images to their original state.
Diffusion models have become a popular choice for use as image generators compared to more traditional methods including, over GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders) for several reasons, as we'll discuss later. But most importantly, diffusion models generate high-quality, photorealistic images that are becoming increasingly difficult for humans to distinguish from non-generated images. Understanding the model architecture will help demonstrate why diffusion models are such a good choice to image generation.
Pre-training diffusion models
Training diffusion models for image generation requires a large dataset of existing images. For instance, if the goal is to train a model that generates images of dogs, you would need thousands of images of different breeds of dogs for the model to learn from.
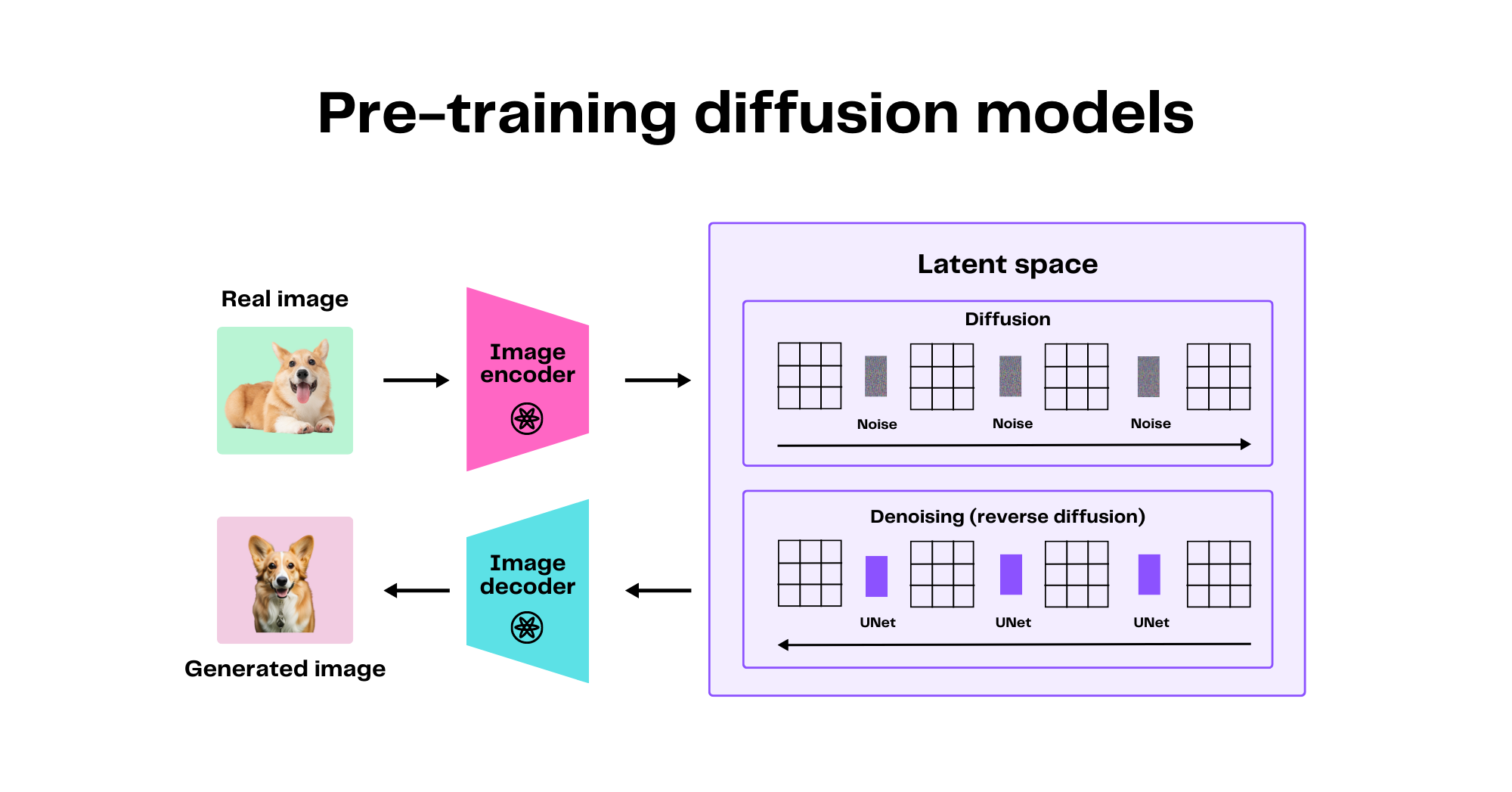
The pre-training process begins by taking a real image, such as a photo of a corgi dog, and feeding it to an image encoder, which transforms the high-dimensional input image into a lower-dimensional representation capturing the essential features of the image while discarding the noise. Once an image passes through the encoder, it's essentially not an image anymore, but rather a vector of numbers that represents all the features of the image. Now the image is embedded in the latent space, a high-dimensional space where each point corresponds to some feature of the data. In the case of images, points in the latent space could represent different breeds, colors, or other characteristics of dogs.
Next, the image undergoes diffusion, a process in which noise is iteratively added to the image with the intention of distorting it. In this context, "noise" refers to random variations or distortions added to the image, gradually obscuring the original details until the image is completely unrecognizable. The image undergoes a transformation until it becomes pure noise. This process, however, is not the end goal. Instead, it serves as a setup for the model to learn the reverse process.

Once the image is completely distorted, it undergoes the process of denoising, in which the model learns to map the noisy images to points in this latent space, capturing the essential features of the images and iteratively reversing the distortions added to the image in the initial diffusion process. The model architecture often used for this task is a UNet. For more information on the components of UNet and a more detailed explanation of diffusion, check out this article by Jay Alammar.
After the vector is denoised, it's sent to the final image decoder, which converts the vector from a numerical representation to a real image, which serves as the final output.
The model is trained using a method that iteratively adjusts its parameters to better predict the original data from the noisy images. This way, the model learns to create new images by reversing the noise addition, turning a point in the latent space into a realistic image.
Running inference on diffusion models
After the diffusion model has been successfully pre-trained or fine-tuned, it's ready to be used to generate novel images. Just as running inference on a transformer, running inference on a diffusion model requires a text prompt, which in this case is an in-depth description of the image you'd like the model to generate.
First, the prompt is run through a text encoder, which transforms the textual description into a numerical representation, often a vector in a high-dimensional space. This representation, which captures the semantic meaning of the prompt, serves as the starting point in the latent space for the image generation process.
The encoded vector then does through the process of diffusion, in which a noisy version of the image is generated based on representations learned during the training phase. The model then begins the denoising process, which it learned during training. It progressively removes the noise from the vector, step by step. The resulting denoised vector is then fed to the image decoder, which converts it from a collection of numbers to an image, which serves as the final output from the model.
Initially, diffusion models were mainly used for generating images from prompts. However, in 2023, the practical applications of diffusion models expanded significantly with the launch of Adobe's Firefly, a suite of generative AI tools integrated into Adobe's existing products. These tools allow users to not only create new images but edit and transform parts of or entire existing images exclusively through prompting.
Advantages of diffusion models
Diffusion models are able to produce high-quality images while also requiring fewer computational resources, compared to other more traditional image generation methods, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). These models experienced a transformative year in 2022, with the release of MidJourney, OpenAI's DALL·E 2, and Google's Imagen. Nevertheless, one model reigns supreme as the queen of diffusion models: Stability AI's Stable Diffusion.
At the time of its release in 2022, the Stable Diffusion model represented a significant leap forward for diffusion models on many fronts. Benefiting from a robust training dataset and a more advanced and efficient model architecture, Stable Diffusion is the current SOTA leader in diffusion models. If you're interested in learning more about the revolutionary nature of Stable Diffusion, I recommend checking out this article on Towards Data Science.
Let's take a look at the advantages of using Stable Diffusion, in particular:
- High-quality output - Output images tend to more accurately reflect their corresponding text prompts and include nuanced details that other models don't capture.
- Computational efficiency - Diffusion models cost less to pre-train (Stable Diffusion only cost ~$600,000) and inference than other competing models due to tweaks in model architecture, like the introduction of FlashAttention to Stable Diffusion.
- Better scaling - Better handling of spatial data means leads to high image quality during both compression and enlargement of images.
Diffusion models will likely become even more efficient and less expensive to pre-train in the future. In fact, in early 2023, MosaicML calculated that it would cost less than $160,000 to train Stable Diffusion from scratch using its own platform. However, it's critical to be aware of the pitfalls and risks of using diffusion models for image generation.
Limitations of diffusion models
- Difficulty handling high-dimensional data - Slight loss of image quality may occur on tasks that require high precision, like dealing with superresolution images.
- Quality control - The probabilistic nature of diffusion models means that they produce varying results for each run, even with identical inputs, which creates challenges in maintaining consistent quality or achieving specific outcomes.
- Deep fakes - Highly realistic outputs exacerbate the risk of exploitation by bad actors who use the models to specifically manipulate images in order to deceive or cause harm to others.
- The technology is new - Because the use of diffusion models for image generation is new, scientists still have a limited understanding of the technology compared to other methods.
- Model bias - Generative models always exacerbate the biases of their training data. Bloomberg journalists already found that Stable Diffusion amplifies toxic stereotypes about race and gender.
Overall, diffusion models have come a long way in the relatively short time they have been used for image generation. In 2022, diffusion models reached a turning point, demonstrating considerable improvements in image generation quality and computational efficiency, with Stable Diffusion reigning supreme. Stable Diffusion's improved model architecture, cost efficiency, and high-quality outputs make it the ideal choice for most image generation tasks. As with transformers, and all other generative machine learning models, diffusion models can produce harmful and misleading content and intensify the existing biases of its training data.
Conclusion
In this article, we've covered how generative models operate, and dove deeper into the pre-training processes behind diffusion and transformer models. Both of these models are trained on large datasets and are especially adept at creating outputs that look remarkably similar to their training data, whether they be images or text. Both types of models have a vast base of general knowledge and can also be fine-tuned on smaller amounts of additional data in order to perform better on specific tasks. Generative machine learning models are extraordinarily powerful, which means that their usage comes with risk. Remember to consider the limitations and ethical implications of individual generative models when using generative AI tools in the real world.
Sources
- The Economist. (2023, April 19). How generative models could go wrong. The Economist.
- Bhatti, B. (2023, February 26). Essential Guide to Foundation Models and Large Language Models. Medium.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G. (2023, February 27). LLaMA: Open and Efficient Foundation Language Models. arXiv.
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B. (2022 April 13). High-Resolution Image Synthesis with Latent Diffusion Models. arXiv.
- Li, C. (2020, June 3). OpenAI's GPT-3 Language Model: A Technical Overview. Lambda.
- Hore, S. (2023, March 13). What are Large Language Models (LLMs)? Analytics Vidhya.
- Raschka, S. (2023, April 23). Finetuning Large Language Models. Ahead of AI.
- Appenzeller, G., Bornstein, M., Casado, M. (2023, April 27). Navigating the High Cost of AI Compute. Andreesson Horowitz.
- Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., Hashimoto, T. (2023, March 13). Alpaca: A Strong, Replicable Instruction-Following Model. Stanford Center for Research on Foundation Models.
- Baum, J., Villasenor, J. (2023, May 8). The politics of AI: ChatGPT and political bias. The Brookings Institution.
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S. (2015, November 8). Deep Unsupervised Learning using Nonequilibrium Thermodynamics. arXiv.
- Romero, A., (2022, August 26). Stable Diffusion Is the Most Important AI Art Model Ever. Towards Data Science.
- Stephenson, C., Seguin, L. (2023, January 24). Training Stable Diffusion from Scratch Costs <$160k. MosaicML.
- Nicoletti, L., Bass, D. (2023). Humans are biased. Generative AI is even worse. Bloomberg.
📝 What is generative AI? A comprehensive guide (GPTech)
📝 Diffusion models made easy (Towards Data Science)
📝 The Illustrated Transformer (Jay Alammar)
📝 The Illustrated Stable Diffusion (Jay Alammar)